Audio-Native Song Recommender
A music recommendation engine built on audio embeddings. It listens to the song itself, not just its metadata.
- Audio-native CLAP embeddings
- 4-axis fused re-rank score
- 8 genres live interactive demo
Context
Most recommenders lean on collaborative filtering: people who liked X liked Y. That works until you hit a cold-start track or a popularity bubble, and it never explains why two songs belong together. I wanted recommendations grounded in how a song actually sounds, and I wanted to prove the pipeline could survive repeated real use instead of dying on a cold start every run.
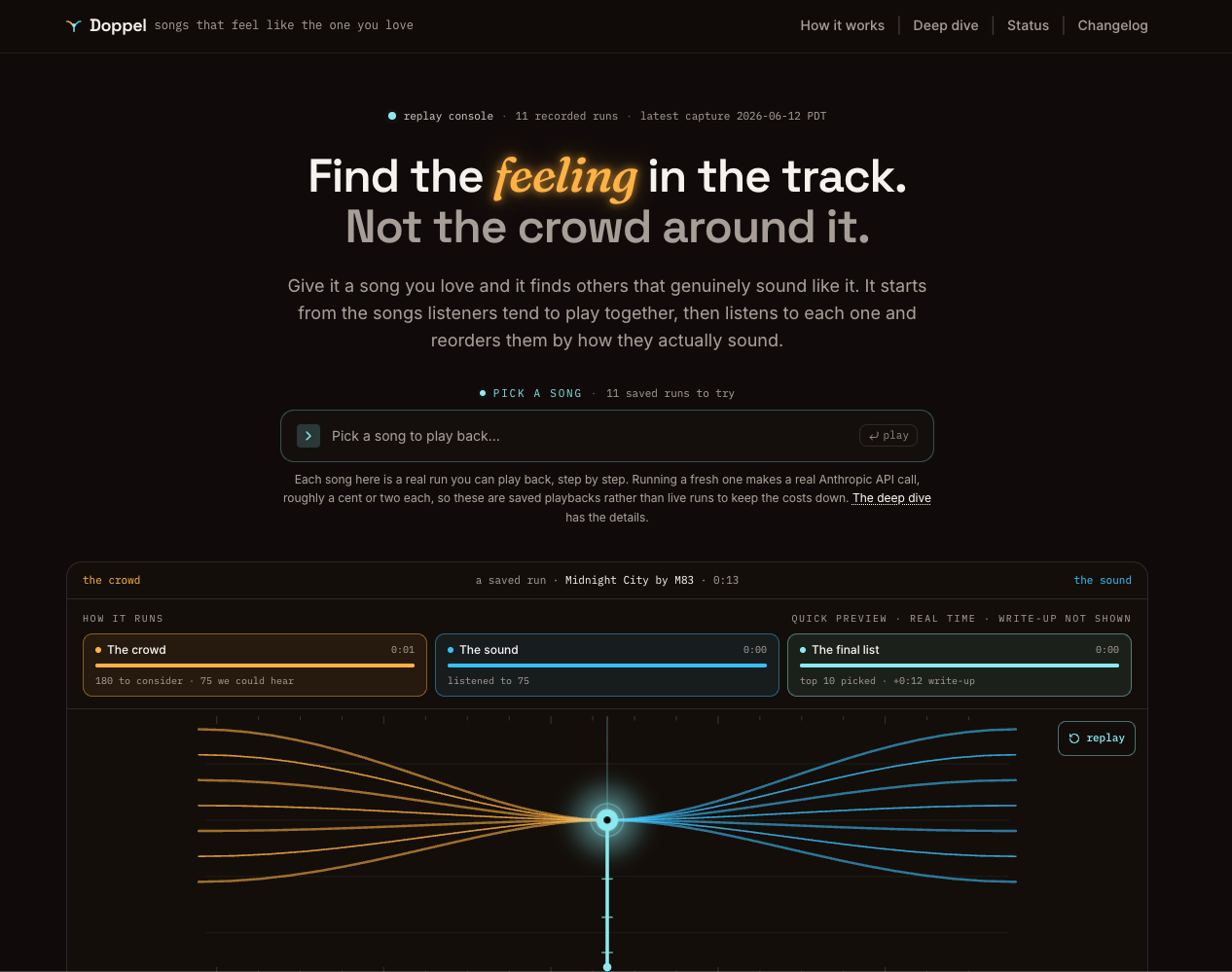
What I built
Doppel, a hybrid retrieve-then-rerank recommender. Cultural candidates come from Last.fm and ListenBrainz, get matched against MusicBrainz, and then get reranked by what the audio itself sounds like. Claude writes the rationale for each pick but never touches the ranking. It is a personal project to go deep on embeddings, vector search, and multi-stage retrieval, end to end.
Architecture
LAION-CLAP turns raw audio into embeddings that capture timbre, energy, and texture. Vectors live in PostgreSQL via pgvector with an HNSW index for fast approximate nearest-neighbor search. Candidates are pulled from Last.fm and ListenBrainz, reconciled against MusicBrainz, then reranked: a fused 4-axis score combines audio cosine, vibe-text cosine, a within-batch rerank, and RRF (reciprocal rank fusion) cultural consensus into one ordering. Claude only explains the result. A Next.js telemetry console exposes every stage so I can see what the pipeline did, not just what it returned.
Technical highlights
- Audio as the rerank signal. Embedding the waveform sidesteps cold start. A brand-new track is just another point in the acoustic space, so it can be ranked without a single play count.
- Lazy self-growing corpus. The vector store fills itself as tracks get requested instead of being precomputed. A cold run takes about 12 minutes; once the corpus is warm, the same run lands near 12 seconds, roughly a 60x cut in repeat-run latency.
- Retrieve, then rerank. Cheap vector search casts a wide net; the fused score does the expensive, nuanced ordering on a short list. It is the standard pattern from modern retrieval systems, and it keeps the LLM out of the ranking loop.
Tradeoffs
Audio embeddings capture sound, not sentiment or cultural context. Two songs can be acoustically close and still a poor pairing, which is exactly why cultural consensus is one of the four axes and not the only signal. Letting Claude explain but never rank keeps the ordering reproducible; the cost is that the prose can rationalize a pick the score made for other reasons.
Outcome
Shipped and live at doppel.erickti.com. Pick one of the seed tracks spanning 8 genres and it returns a real top-10 with the 4-axis score breakdown, source overlap, and an LLM rationale for every neighbor. I validated it against a 19-seed eval across those 8 genres, and the telemetry console makes each run inspectable. It is my end-to-end deep dive into a retrieval system built to keep running, not just to demo once.